I hope you enjoyed our previous newsletter on how inductive and selection bias help in future of predictive data analytics. Let’s continue to our previous discussion with new topic NO FREE LUNCH THEOREM & GOLDILOCKS METHOD.
Let’s start with first NO FREE LUNCH THEOREM:
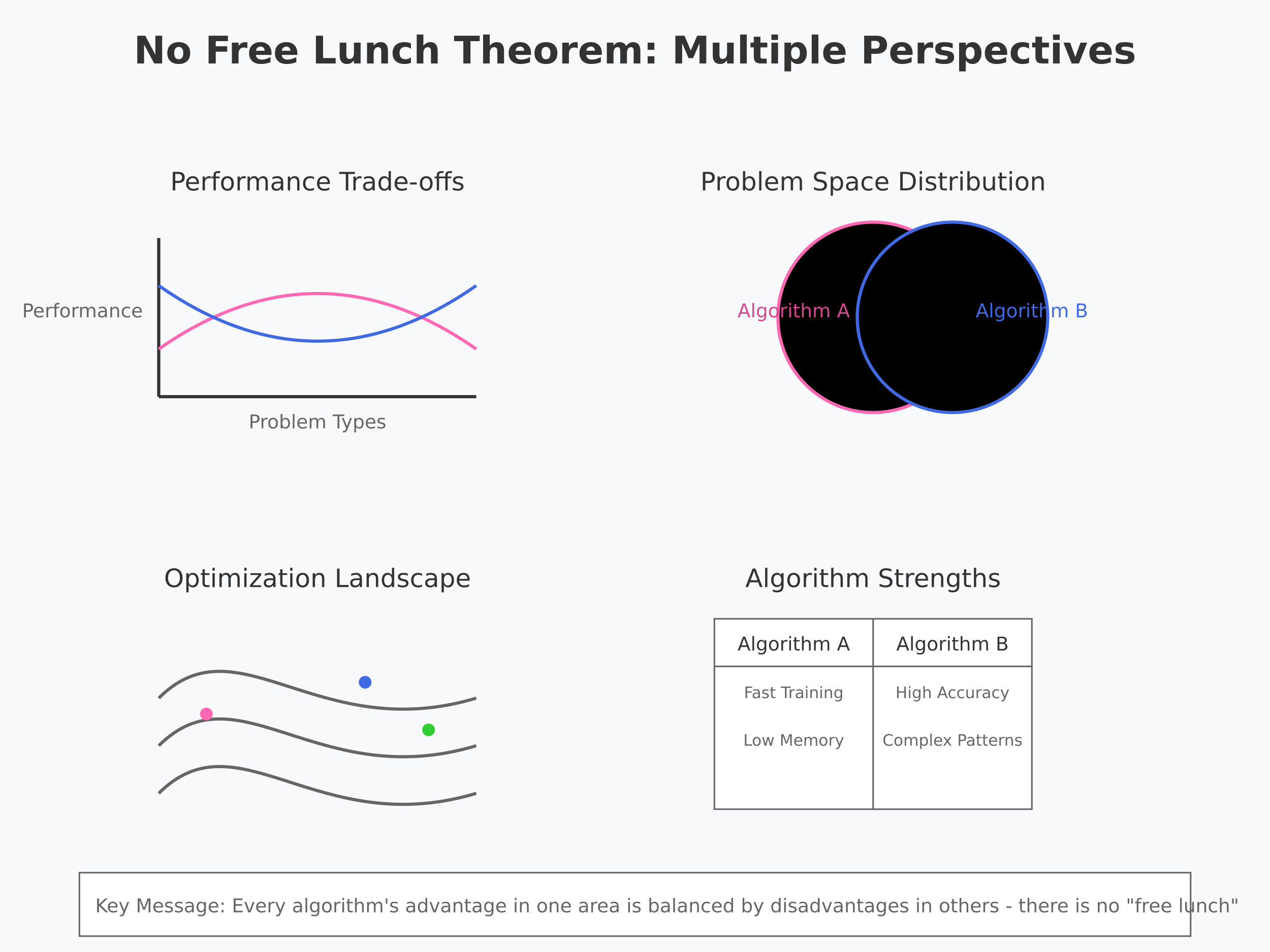
•The No Free Lunch (NFL) Theorem is a concept in machine learning and optimization that essentially says: "There is no one-size-fits-all solution." In other words, no single algorithm works best for every possible problem.
•What It Means
•The theorem states that if you average the performance of all algorithms over all possible problems, every algorithm will perform equally well (or equally poorly). This means that an algorithm that works great on one problem might perform poorly on another, and there's no single "best" algorithm for every situation.
•Simple Example
•Imagine you're trying to guess the winning lottery numbers for different lottery games. If you use the same strategy (like picking numbers based on birthdays) for every game, it might work well for one type of lottery, but it could completely fail for another. You need different strategies for different games.
•Key Takeaways
1.No Universal Best Algorithm: There isn't a single best machine learning model or algorithm that will work for all datasets or problems. Each problem may require a different approach.
2.Tailor Your Approach: To get the best results, you need to understand the specifics of the problem and choose or customize the algorithm accordingly.
3.Experimentation is Necessary: In practice, you often have to try several algorithms and see which one works best for your specific problem. This is why techniques like cross-validation and model comparison are so crucial in machine learning.
•Why It Matters
The No Free Lunch Theorem reminds us that machine learning isn’t magic—it's about finding the right tool for the job. It encourages experimentation and adaptation instead of relying on one algorithm to solve everything
Now,
GOLDILOCKS METHOD:
Underfitting:
•Underfitting happens when a machine learning model is too simple to capture the underlying patterns in the data. It fails to learn enough from the training data, leading to poor performance both on the training set and new, unseen data.
•What It Means
•An underfitted model hasn’t learned the relationships in the data, so it makes inaccurate predictions. This usually happens if the model is too simple, has too few features, or hasn't been trained long enough.
•Simple Example
•Imagine you're trying to fit a straight line to a set of data points that clearly follow a curve. A straight line is too simple to match the curve, so it misses the trend in the data. This is underfitting—the model doesn't capture what's really going on.
•Signs of Underfitting
1.High Training Error: The model performs poorly even on the data it was trained on.
2.High Testing Error: The model also fails to make good predictions on new data.
Too Simple Model: Often, a very basic model (like a linear model for complex data) will underfit.
Goldilocks Methods:
•The Goldilocks Method in machine learning is about finding the "just right" balance between a model that is too simple (underfitting) and a model that is too complex (overfitting). The goal is to create a model that is complex enough to capture the underlying patterns in the data but not so complex that it captures noise or irrelevant details.
•How It Works
1.Avoid Underfitting: If the model is too simple, it won't learn enough from the data (underfitting). This is like a chair that's too small—it doesn’t fit well.
2.Avoid Overfitting: If the model is too complex, it will memorize the training data, including noise (overfitting). This is like a chair that's too big—it tries to do too much.
3.Find the Sweet Spot: The Goldilocks Method involves experimenting with model complexity, features, parameters, and data until the model generalizes well to new, unseen data—finding the balance where it’s "just right. “
•Key Techniques for the Goldilocks Method
•
1.Cross-Validation: Use cross-validation to test the model’s performance on multiple subsets of the data. This helps ensure that the model generalizes well and is not overfitting.
2.Regularization: Use regularization techniques (like L1 or L2) to control complexity, guiding the model to focus on the most important features.
3.Feature Engineering: Carefully choose or create features that capture the right level of information without adding unnecessary complexity.
4.Hyperparameter Tuning: Adjust the hyperparameters of your model to find the optimal settings. Tools like grid search or random search can help explore the parameter space.
5.Monitoring Learning Curves: Plot learning curves to see how error decreases on both training and validation data as you adjust model complexity. A good balance shows improvement on both without overfitting.
Thank you for joining us! if you enjoyed this edition, consider giving it a like. We’d love to hear your thoughts-drop a comment below!
Loading...
Thanks for reading Amit kumar! Subscribe for free to receive new posts and support my work.