Machine Learning for Predictive Data Analytics

Predictive data analytics- is a art of building and using models that make predictions based on patterns extracted from historical data. To train models we use machine learning.
What is Machine Learning?
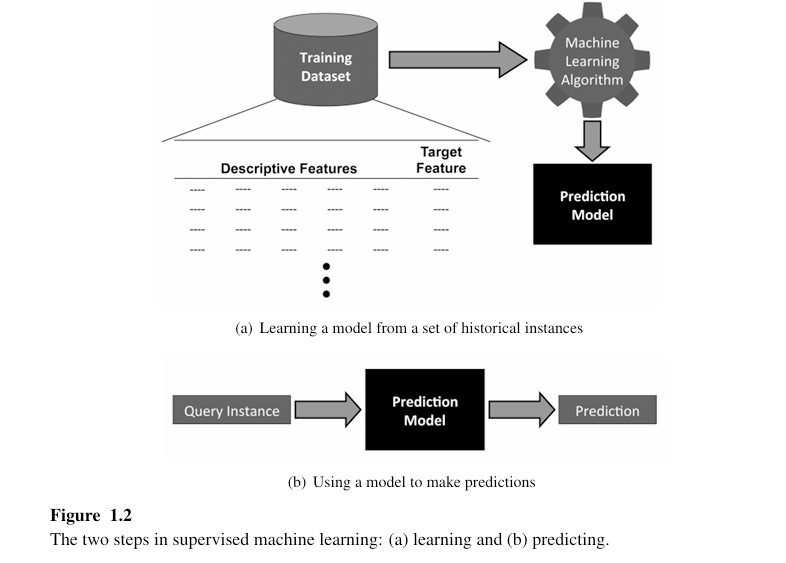
Automated process that extracts patterns from data. To build the models used in predictive data analytics applications , we use supervised machine learning.
Supervised machine learning – Techniques automatically learn a model of the relationship between a set of descriptive features and target feature based on a set of historical examples.
•Overall dataset is referred as training dataset
•Each row in dataset is referred as a training instances
How Does Machine learning work?
Machine learning algorithms works by searching through a set of possible prediction models for the model that best captures the relationship between the descriptive features and target features in a dataset. An obvious criteria for driving this search is to look for models that that are consistent with the data.
•There are at least two reasons why simply searching for consistent models is not sufficient for learning useful prediction models.
1.When we are dealing with large datasets ,it is likely that there is noise in data(some of the feature values will be mislabeled) and prediction models that are consistent with noisy data make incorrect prediction.
2.In the vast majority of machine learning projects ,the training set represents only a small sample of the possible set of instances in the domain. As result machine learning is an ill-poised problem ,that is , a problem for which a unique solution cannot be determined using only the information that available.
Consistent model- A model is consistent with the dataset if there are no instances for which it makes an incorrect prediction, you are essentially describing a perfect model fit for that dataset. This means the model has achieved 100% accuracy on the dataset.
However, just because a model is perfect on one dataset doesn’t mean it will be perfect on new data. Sometimes, a model can memorize the exact data it’s trained on instead of learning the real patterns. To be sure the model is truly "smart" and not just memorizing, we need to check how well it performs on a different set of data it hasn’t seen before.
Labeled Dataset – includes values for the target features.
To learn a prediction model for the scenario by searching for a model that is consistent with the dataset .The first thing we need to do is to figure out how many different possible models actually exist for the scenario.
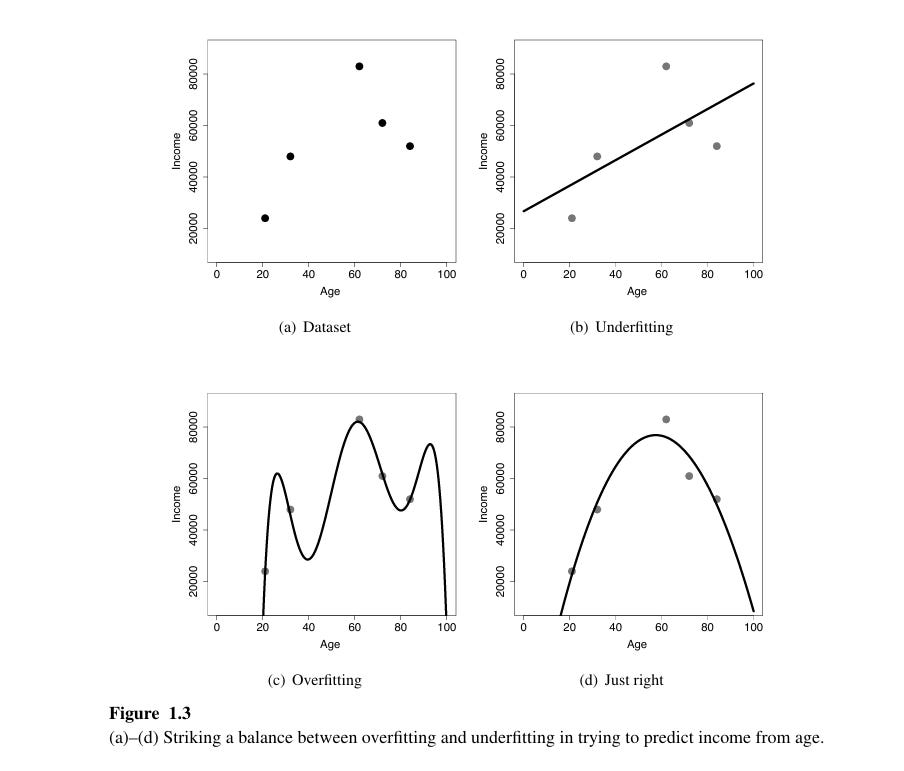
•overfitting in machine learning. When multiple models fit the training data perfectly, it might seem advantageous because they all make accurate predictions for the known instances. However, the real challenge arises when these models are applied to unseen data (instances not in the training set). Different models that fit the training data equally well might make conflicting predictions on new data, indicating that they have learned the noise or irrelevant details of the training set instead of general patterns.
•What It Means
•An overfitted model has learned not only the real patterns in the data but also the random quirks or noise. It memorizes the training data instead of generalizing the underlying trends, making it less effective on new examples.
•Simple Example
•Imagine you’re studying for a test by memorizing every question and answer from past exams. On those exact exams, you’d do great, but if the questions change slightly or new ones are added, you'd struggle. Overfitting is like this—your model "memorizes" instead of "understanding.“
•Signs of Overfitting
1.Low Training Error: The model performs very well on the training data, often with extremely high accuracy.
2.High Testing Error: The model fails to generalize, leading to poor performance on new or unseen data.
3.Too Complex Model: The model has too many parameters or complexity relative to the size and complexity of the data (like a deep neural network for a small, simple dataset).
Techniques like cross-validation, regularization, and using a validation set help in selecting a model that generalizes well to new data.
•All the different model selection criteria consists of a set of assumptions about the characteristics of model the we would like the algorithm to induce .The set of assumptions that defines the model selection criteria of machine learning algorithm is known as the inductive bias of the machine learning algorithm.
•Inductive bias-It refers to the set of assumptions a machine learning model makes to predict outcomes for unseen data. Since there are often many possible explanations for the training data, a model needs some form of bias to generalize beyond it—to make educated guesses about new data it hasn't encountered before.
•Think of it like this: if you see a few dogs, and they all have tails, you might assume all dogs have tails. That assumption is your inductive bias—it helps you make predictions about dogs you've never seen before.
•Inductive learning- learning a general rule from a finite set of examples.